|
|
0.6.0
|
|
|
0.6.0
|
Variables associated with domain partitioning context. More...
Variables | |
| integer | rank = 0 |
| Rank for the current local domain (associated to an MPI process). | |
| type(mpi_comm) | mpi_comm_notus |
| Notus MPI communicator (Cartesian aware). This variable is initialized to mpi_comm_world in the early stage of Notus initialization? | |
Numbers of local domains. | |
Total number of local domains. | |
| integer | n_mpi_proc = 1 |
| integer | n_mpi_proc_x = 1 |
| Number of local domains along the x-axis. | |
| integer | n_mpi_proc_y = 1 |
| Number of local domains along the y-axis. | |
| integer | n_mpi_proc_z = 1 |
| Number of local domains along the z-axis. | |
| integer, dimension(:), allocatable | proc_direction |
Values n_mpi_proc_x, n_mpi_proc_y, n_mpi_proc_z stored in an array. | |
| integer, dimension(:), allocatable | proc_coordinate |
| Coordinates of the current local domain in the Cartesian processor grid. | |
| logical | is_repartitioning = .false. |
| Will the domain be repartitioned? | |
| logical | is_repartitioning_achieved = .false. |
| Has the repartitioning process been already achieved? | |
| logical | is_initial_step_repartitioning = .true. |
| Is it the initial step in the repartitioning process? If so, stop the calculation and print the required number of processors. | |
| integer | n_cells_proc = 0 |
| Number of cells per partition. | |
| integer | label_wanted_partitioning = -1 |
| Label of the wanted partitioning. | |
Neighborhood information. | |
Domain ranks for the six neighbors. The value Give the rank of any domain from its relative coordinates. | |
| integer, dimension(:,:,:), allocatable | neighbor_proc |
| integer, dimension(:), allocatable | neighbor_proc_list |
| Give the list of the neighboring processors in the repartitioning process. | |
| integer, dimension(:,:), allocatable | neighbor_points_list |
| Give the start and end indices of the points to exchange between neighbor processors. | |
| logical | mpi_exchange_full = .true. |
| MPI exchange including corners (and edges in 3D) | |
| integer | n_exchange_proc = -1 |
| Number of neighbor domains to communicate with. | |
Processor information with respect to boundaries. | |
False or true depending whether they are at a physical boundary or not Is the processor on the left boundary of the domain | |
| logical | is_proc_on_left_boundary = .false. |
| logical | is_proc_on_right_boundary = .false. |
| Is the processor on the right boundary of the domain. | |
| logical | is_proc_on_bottom_boundary = .false. |
| Is the processor on the bottom boundary of the domain. | |
| logical | is_proc_on_top_boundary = .false. |
| Is the processor on the top boundary of the domain. | |
| logical | is_proc_on_back_boundary = .false. |
| Is the processor on the back boundary of the domain. | |
| logical | is_proc_on_front_boundary = .false. |
| Is the processor on the front boundary of the domain. | |
Periodic information (location of the periodic boundary) | |
These variables are set ONLY IF there are more than one proc in the given direction. Example 1: 'is_proc_on_left_periodic == .false.' if 'is_periodic_x == .true.' and 'n_mpi_proc_x == 1'. Example 2: 'is_proc_on_left_periodic == .true.' if 'is_periodic_x == .true.' and 'n_mpi_proc_x > 1' and 'is_proc_on_left_boundary'. | |
| logical | is_proc_on_left_periodic = .false. |
| logical | is_proc_on_right_periodic = .false. |
| logical | is_proc_on_top_periodic = .false. |
| logical | is_proc_on_bottom_periodic = .false. |
| logical | is_proc_on_back_periodic = .false. |
| logical | is_proc_on_front_periodic = .false. |
Local domain start and end indices in the physical domain (with no ghost cells) | |
indexing. | |
| integer | is_global_physical_domain = 1 |
| integer | is_global_physical_domain_r = 1 |
| integer | is_global_physical_domain_t = 1 |
| integer | js_global_physical_domain = 1 |
| integer | js_global_physical_domain_r = 1 |
| integer | js_global_physical_domain_t = 1 |
| integer | ks_global_physical_domain = 1 |
| integer | ks_global_physical_domain_r = 1 |
| integer | ks_global_physical_domain_t = 1 |
| integer | ie_global_physical_domain = 1 |
| integer | ie_global_physical_domain_r = 1 |
| integer | ie_global_physical_domain_t = 1 |
| integer | je_global_physical_domain = 1 |
| integer | je_global_physical_domain_r = 1 |
| integer | je_global_physical_domain_t = 1 |
| integer | ke_global_physical_domain = 1 |
| integer | ke_global_physical_domain_r = 1 |
| integer | ke_global_physical_domain_t = 1 |
| integer | isu_global_physical_domain = 1 |
| integer | ieu_global_physical_domain = 1 |
| integer | jsv_global_physical_domain = 1 |
| integer | jev_global_physical_domain = 1 |
| integer | ksw_global_physical_domain = 1 |
| integer | kew_global_physical_domain = 1 |
Local domain start and end indices in the overlapping numerical domain (with boundary and overlapping boundary cells) | |
indexing. | |
| integer | is_global_overlap_numerical_domain = 1 |
| integer | is_global_overlap_numerical_domain_r = 1 |
| integer | is_global_overlap_numerical_domain_t = 1 |
| integer | js_global_overlap_numerical_domain = 1 |
| integer | js_global_overlap_numerical_domain_r = 1 |
| integer | js_global_overlap_numerical_domain_t = 1 |
| integer | ks_global_overlap_numerical_domain = 1 |
| integer | ks_global_overlap_numerical_domain_r = 1 |
| integer | ks_global_overlap_numerical_domain_t = 1 |
| integer | ie_global_overlap_numerical_domain = 1 |
| integer | ie_global_overlap_numerical_domain_r = 1 |
| integer | ie_global_overlap_numerical_domain_t = 1 |
| integer | je_global_overlap_numerical_domain = 1 |
| integer | je_global_overlap_numerical_domain_r = 1 |
| integer | je_global_overlap_numerical_domain_t = 1 |
| integer | ke_global_overlap_numerical_domain = 1 |
| integer | ke_global_overlap_numerical_domain_r = 1 |
| integer | ke_global_overlap_numerical_domain_t = 1 |
Coordinates of the left, bottom, back corner. | |
| double precision, dimension(:), allocatable | global_domain_corners1_x |
| double precision, dimension(:), allocatable | global_domain_corners1_y |
| double precision, dimension(:), allocatable, target | global_domain_corners1_z |
| double precision, dimension(:), allocatable | global_domain_corners2_x |
| Coordinates of the right, top, front corner. | |
| double precision, dimension(:), allocatable | global_domain_corners2_y |
| double precision, dimension(:), allocatable, target | global_domain_corners2_z |
List of all partition sizes. | |
The arrays starts at zero en ends on n_mpi_proc_*-1. E.g.: | |
| integer, dimension(:), allocatable | global_domain_list_nx |
| integer, dimension(:), allocatable | global_domain_list_nx_r |
| integer, dimension(:), allocatable | global_domain_list_nx_t |
| integer, dimension(:), allocatable | global_domain_list_ny |
| integer, dimension(:), allocatable | global_domain_list_ny_r |
| integer, dimension(:), allocatable | global_domain_list_ny_t |
| integer, dimension(:), allocatable | global_domain_list_nz |
| integer, dimension(:), allocatable | global_domain_list_nz_r |
| integer, dimension(:), allocatable | global_domain_list_nz_t |
List of the starting indices of the faces of all partitions. | |
The arrays starts at zero en ends on n_mpi_proc_*-1. E.g.: | |
| integer, dimension(:), allocatable | global_domain_list_isu |
| integer, dimension(:), allocatable | global_domain_list_isu_r |
| integer, dimension(:), allocatable | global_domain_list_isu_t |
| integer, dimension(:), allocatable | global_domain_list_jsv |
| integer, dimension(:), allocatable | global_domain_list_jsv_r |
| integer, dimension(:), allocatable | global_domain_list_jsv_t |
| integer, dimension(:), allocatable | global_domain_list_ksw |
| integer, dimension(:), allocatable | global_domain_list_ksw_r |
| integer, dimension(:), allocatable | global_domain_list_ksw_t |
List of the ending indices of the faces of all partitions. | |
The arrays starts at zero en ends on n_mpi_proc_*-1. E.g.: | |
| integer, dimension(:), allocatable | global_domain_list_ieu |
| integer, dimension(:), allocatable | global_domain_list_ieu_r |
| integer, dimension(:), allocatable | global_domain_list_ieu_t |
| integer, dimension(:), allocatable | global_domain_list_jev |
| integer, dimension(:), allocatable | global_domain_list_jev_r |
| integer, dimension(:), allocatable | global_domain_list_jev_t |
| integer, dimension(:), allocatable | global_domain_list_kew |
| integer, dimension(:), allocatable | global_domain_list_kew_r |
| integer, dimension(:), allocatable | global_domain_list_kew_t |
Variables associated with domain partitioning context.
The global domain is partitioned in a Cartesian arrangement of local domains, as described in computational_domain. The numbers of local domain per direction are n_mpi_proc_x, n_mpi_proc_y, and n_mpi_proc_z, and the total number local domains is n_mpi_proc = prox_nb_x × n_mpi_proc_y × n_mpi_proc_z. Each local domain is identified by its coordinates proc_coordinate in the partitioning system, and also by its rank. Both coordinates and ranks ranges from 0 to some n-1.
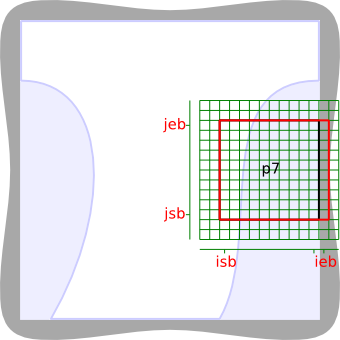
The module variables are defined within the context of a local domain (SIMD paradigm); they are distributed or local variables. Although, some variables have the same value for each local domain, thus can be considered as a shared or global variable.
As described in computational_domain, the mesh is indexed locally over an extended domain, the numerical domain. It is sometimes necessary to define a global indexing.
Refined grid (under development): grid can be globally refined for phase advection. Suffix _r is associated to the refined grids, suffix _t is associated to the temporary grid.
| double precision, dimension(:), allocatable variables_mpi::global_domain_corners1_x |
| double precision, dimension(:), allocatable variables_mpi::global_domain_corners1_y |
| double precision, dimension(:), allocatable, target variables_mpi::global_domain_corners1_z |
| double precision, dimension(:), allocatable variables_mpi::global_domain_corners2_x |
Coordinates of the right, top, front corner.
| double precision, dimension(:), allocatable variables_mpi::global_domain_corners2_y |
| double precision, dimension(:), allocatable, target variables_mpi::global_domain_corners2_z |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_ieu |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_ieu_r |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_ieu_t |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_isu |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_isu_r |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_isu_t |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_jev |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_jev_r |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_jev_t |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_jsv |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_jsv_r |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_jsv_t |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_kew |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_kew_r |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_kew_t |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_ksw |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_ksw_r |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_ksw_t |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_nx |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_nx_r |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_nx_t |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_ny |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_ny_r |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_ny_t |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_nz |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_nz_r |
| integer, dimension(:), allocatable variables_mpi::global_domain_list_nz_t |
| integer variables_mpi::ie_global_overlap_numerical_domain = 1 |
| integer variables_mpi::ie_global_overlap_numerical_domain_r = 1 |
| integer variables_mpi::ie_global_overlap_numerical_domain_t = 1 |
| integer variables_mpi::ie_global_physical_domain = 1 |
| integer variables_mpi::ie_global_physical_domain_r = 1 |
| integer variables_mpi::ie_global_physical_domain_t = 1 |
| integer variables_mpi::ieu_global_physical_domain = 1 |
| integer variables_mpi::is_global_overlap_numerical_domain = 1 |
| integer variables_mpi::is_global_overlap_numerical_domain_r = 1 |
| integer variables_mpi::is_global_overlap_numerical_domain_t = 1 |
| integer variables_mpi::is_global_physical_domain = 1 |
| integer variables_mpi::is_global_physical_domain_r = 1 |
| integer variables_mpi::is_global_physical_domain_t = 1 |
| logical variables_mpi::is_initial_step_repartitioning = .true. |
Is it the initial step in the repartitioning process? If so, stop the calculation and print the required number of processors.
| logical variables_mpi::is_proc_on_back_boundary = .false. |
Is the processor on the back boundary of the domain.
| logical variables_mpi::is_proc_on_back_periodic = .false. |
| logical variables_mpi::is_proc_on_bottom_boundary = .false. |
Is the processor on the bottom boundary of the domain.
| logical variables_mpi::is_proc_on_bottom_periodic = .false. |
| logical variables_mpi::is_proc_on_front_boundary = .false. |
Is the processor on the front boundary of the domain.
| logical variables_mpi::is_proc_on_front_periodic = .false. |
| logical variables_mpi::is_proc_on_left_boundary = .false. |
| logical variables_mpi::is_proc_on_left_periodic = .false. |
| logical variables_mpi::is_proc_on_right_boundary = .false. |
Is the processor on the right boundary of the domain.
| logical variables_mpi::is_proc_on_right_periodic = .false. |
| logical variables_mpi::is_proc_on_top_boundary = .false. |
Is the processor on the top boundary of the domain.
| logical variables_mpi::is_proc_on_top_periodic = .false. |
| logical variables_mpi::is_repartitioning = .false. |
Will the domain be repartitioned?
| logical variables_mpi::is_repartitioning_achieved = .false. |
Has the repartitioning process been already achieved?
| integer variables_mpi::isu_global_physical_domain = 1 |
| integer variables_mpi::je_global_overlap_numerical_domain = 1 |
| integer variables_mpi::je_global_overlap_numerical_domain_r = 1 |
| integer variables_mpi::je_global_overlap_numerical_domain_t = 1 |
| integer variables_mpi::je_global_physical_domain = 1 |
| integer variables_mpi::je_global_physical_domain_r = 1 |
| integer variables_mpi::je_global_physical_domain_t = 1 |
| integer variables_mpi::jev_global_physical_domain = 1 |
| integer variables_mpi::js_global_overlap_numerical_domain = 1 |
| integer variables_mpi::js_global_overlap_numerical_domain_r = 1 |
| integer variables_mpi::js_global_overlap_numerical_domain_t = 1 |
| integer variables_mpi::js_global_physical_domain = 1 |
| integer variables_mpi::js_global_physical_domain_r = 1 |
| integer variables_mpi::js_global_physical_domain_t = 1 |
| integer variables_mpi::jsv_global_physical_domain = 1 |
| integer variables_mpi::ke_global_overlap_numerical_domain = 1 |
| integer variables_mpi::ke_global_overlap_numerical_domain_r = 1 |
| integer variables_mpi::ke_global_overlap_numerical_domain_t = 1 |
| integer variables_mpi::ke_global_physical_domain = 1 |
| integer variables_mpi::ke_global_physical_domain_r = 1 |
| integer variables_mpi::ke_global_physical_domain_t = 1 |
| integer variables_mpi::kew_global_physical_domain = 1 |
| integer variables_mpi::ks_global_overlap_numerical_domain = 1 |
| integer variables_mpi::ks_global_overlap_numerical_domain_r = 1 |
| integer variables_mpi::ks_global_overlap_numerical_domain_t = 1 |
| integer variables_mpi::ks_global_physical_domain = 1 |
| integer variables_mpi::ks_global_physical_domain_r = 1 |
| integer variables_mpi::ks_global_physical_domain_t = 1 |
| integer variables_mpi::ksw_global_physical_domain = 1 |
| integer variables_mpi::label_wanted_partitioning = -1 |
Label of the wanted partitioning.
| type(mpi_comm) variables_mpi::mpi_comm_notus |
Notus MPI communicator (Cartesian aware). This variable is initialized to mpi_comm_world in the early stage of Notus initialization?
| logical variables_mpi::mpi_exchange_full = .true. |
MPI exchange including corners (and edges in 3D)
| integer variables_mpi::n_cells_proc = 0 |
Number of cells per partition.
| integer variables_mpi::n_exchange_proc = -1 |
Number of neighbor domains to communicate with.
| integer variables_mpi::n_mpi_proc = 1 |
| integer variables_mpi::n_mpi_proc_x = 1 |
Number of local domains along the x-axis.
| integer variables_mpi::n_mpi_proc_y = 1 |
Number of local domains along the y-axis.
| integer variables_mpi::n_mpi_proc_z = 1 |
Number of local domains along the z-axis.
| integer, dimension(:,:), allocatable variables_mpi::neighbor_points_list |
Give the start and end indices of the points to exchange between neighbor processors.
| integer, dimension(:,:,:), allocatable variables_mpi::neighbor_proc |
| integer, dimension(:), allocatable variables_mpi::neighbor_proc_list |
Give the list of the neighboring processors in the repartitioning process.
| integer, dimension(:), allocatable variables_mpi::proc_coordinate |
Coordinates of the current local domain in the Cartesian processor grid.
| integer, dimension(:), allocatable variables_mpi::proc_direction |
Values n_mpi_proc_x, n_mpi_proc_y, n_mpi_proc_z stored in an array.
| integer variables_mpi::rank = 0 |
Rank for the current local domain (associated to an MPI process).